

Markdown to Medium via PHP and the Medium API
I am trying to get the word out about this blog. Like many coders and writers, my skills are more focussed on coding and writing than marketing. One way of finding new readers is to cross-post articles to Medium. I write almost exclusively in Markdown these days. It’s been a while since I’ve worked with Medium, and I was surprised that, though it’s excellent, the Medium editor is not immediately markdown-friendly. Now, of course, I could paste each article I want to share into Medium’s editing window. Then I could work through it, manually marking up my Markdown. Life is too short for such work.
I thought I’d found the answer when, after a little research, I found that Medium lets you import from a Web page. For many writers, in fact, this solution would probably work. But, as I discovered, if you’re sharing code examples you may find that your all-important listings end up stripped out of the import.
My next stop? The API, of course. It didn’t take long to find POST /users/{{authorId}}/posts and to discover that part of the payload is a contentFormat parameter:
The format of the “content” field. There are two valid values, “html”, and “markdown”
Jackpot! So let’s do it.
There’s always a key
Medium makes it pretty easy to get a key. Once you’ve signed up for an account Hit the user menu in the top right hand side corner, and choose ‘Settings’. Then, in the main window select the ‘Security and apps’ tab. You’ll find ‘Integration tokens’ at the bottom of the list.
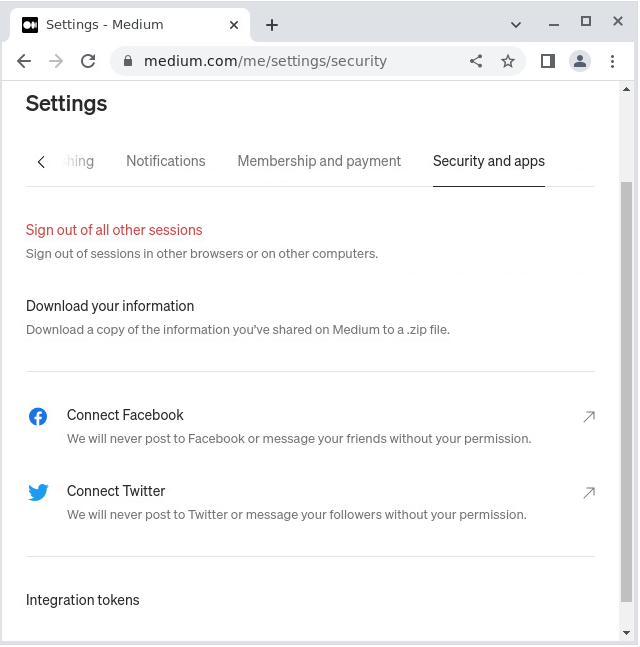
Admittedly, that’s possibly a quirky usage of the word ‘easy’. It reminds me a little of this quote from The Hitchhiker’s Guide to the Galaxy:
“But the plans were on display . . .”
“On display? I eventually had to go down to the cellar to find them.”
“That’s the display department.”
“With a torch.”
“Ah, well the lights had probably gone.”
“So had the stairs.”
“But look, you found the notice, didn’t you?”
“Yes,” said Arthur, “yes I did. It was on display in the bottom of a locked filing cabinet stuck in a disused lavatory with a sign on the door saying Beware of the Leopard.”
Still, most users won’t be looking for API tokens so a less than prominent placement is understandable. Also, we’re not asked to register an application or wait for approval, so I’m sticking with easy
You’ll be presented with simple form through which you can create and copy your key.
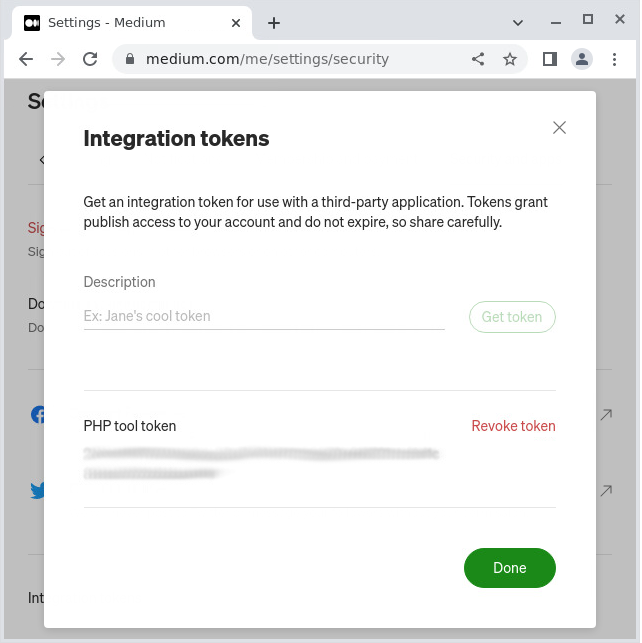
And we’re ready..
Making contact
The Medium API provides a handy confirmation endpoint: GET /me which returns the authenticated user’s details.
In order to make my request, I need to first work out how I should authenticate myself. What do I do with my token? The API documentation provides a sample request:
GET /v1/me HTTP/1.1
Host: api.medium.com
Authorization: Bearer 181d415f34379af07b2c11d144dfbe35d
Content-Type: application/json
Accept: application/json
Accept-Charset: utf-8
So the token needs to be sent as an Authorization token. Let’s replicate that using PHP’s cURL extension:
class HelloMe
{
private $intToken;
private $baseUrl = 'https://api.medium.com/v1/';
public function __construct($intToken)
{
$this->intToken = $intToken;
}
public function getMe(): \stdClass
{
$url = $this->baseUrl . 'me';
$headers = array(
'Authorization: Bearer ' . $this->intToken,
'Content-Type: application/json'
);
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
$info = curl_getinfo($ch);
if ($info['http_code'] != 200) {
throw new \Exception("GET error for: $url: $response");
}
curl_close($ch);
return json_decode($response);
}
}
I’ve called this proof of concept class HelloMe. The API’s base URL is https://api.medium.com/v1/ and I include that as a property. The constructor requires a token – which is then also stored. The real action takes place in the getMe() method which assembles a full URL, sets up the Authorization header and makes the request. I am expecting an HTTP response code of 200 and, if I don’t get that, I throw an exception. Otherwise, I simply run json_decode() on the response and return the result.
Let’s try the code:
$path = __DIR__ . "/../conf/conf.json";
$conf = json_decode(file_get_contents($path), true);
$token = $conf['medium']['token'];
$hellome = new HelloMe($token);
$me = $hellome->getMe();
After a little work to get the token from a configuration file, I simply instantiate the HelloMe class then call getMe(). When I run the result through print_r() I should see something like this:
me: stdClass Object
(
[data] => stdClass Object
(
[id] => 1f01b1cb3b51cd4f711bee23ac36ba2603ced6ae47c39873b3ab9a791e61c75ea
[username] => getinstance_mz
[name] => Matt Zandstra
[url] => https://medium.com/@getinstance_mz
[imageUrl] => https://cdn-images-1.medium.com/fit/c/400/400/1*dmbNkD5D-u45r44go_cf0g.png
)
)
So contact is established. Let’s post an article!
Generating a first article
As we have seen, the endpoint in question here is POST /users/{{authorId}}/posts. Thanks to getMe() we now have the means to construct the endpoint instance.
The required fields for the endpoint are title, contentFormat, and content. The title field is not used in the post itself. You’ll need to add a heading to the content itself for that. contentFormat can be one of ‘html’ and ‘markdown’. Of the other parameters, perhaps the most crucial is publishStatus. This can be one of public, draft, and unlisted. I suggest we hardcode draft so that we don’t send any errors out into the world.
NOTE The API documentation provides a handy table with all available parameters for the endpoint. Note, in particular, the
canonicalUrlparameter which might be relevant if you’re promoting an original post from elsewhere on the Web.
Let’s implement an addArticle() method:
public function addArticle(string $title, string $content): \stdClass
{
$endpoint = 'users/' . $this->getMe()->data->id . '/posts';
$url = $this->baseUrl . $endpoint;
$data = [
'title' => $title,
'contentFormat' => 'markdown',
'content' => $content,
'publishStatus' => 'draft'
];
$ch = curl_init();
$headers = array(
'Authorization: Bearer ' . $this->intToken,
'Content-Type: application/json'
);
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $headers);
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($data));
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
curl_close($ch);
$info = curl_getinfo($ch);
if ($info['http_code'] != 201) {
throw new \Exception("POST error for: $url: $response");
}
return json_decode($response);
}
As you can see, this more or less echoes getMe(). The main difference, of course, is that we’re making a POST request, and passing along different parameters to a different endpoint. Note how we call getMe() to acquire the authorId value. In a more sophisticated implementation we might cache this information to save the extra request.
Let’s try it out:
$hellome = new HelloMe($token);
$article = <<<ARTICLE
# Welcome
This is an article
```php
print "with a hello world";
```
## And a sub head
> with a blockquote containing something **bold**.
## Thank you
ARTICLE;
$resp = $hellome->addArticle("A test article", $article);
That runs for me without error. And, as if by magic, the draft appears in my Stories list.
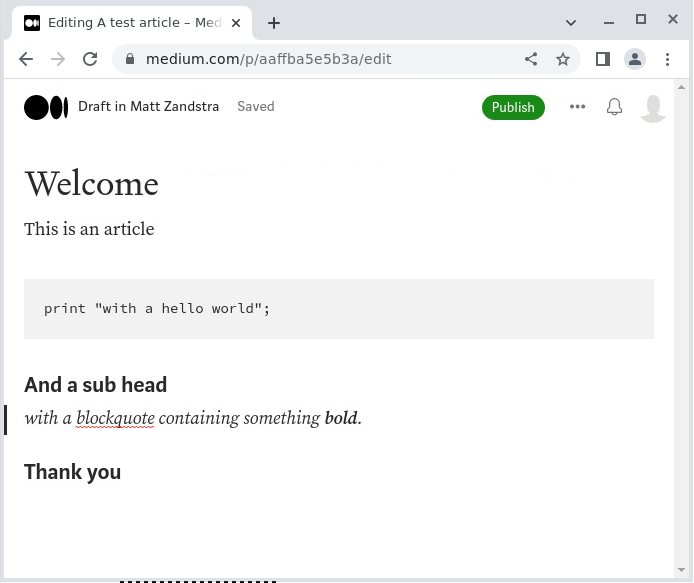
Is that good enough? Well, it depends upon whether you use screen grabs and other artwork. If you agree that life is too short to spend time formatting code examples, you’re also probably keen not to waste any effort uploading images.
But, before we get to that, I have an itch to refactor the HelloMe class.
A pause to refactor
I often to take this step after a concept is proved in a project. Without a quick look at design issues, short cuts in code can quickly be baked into a project and cause problems down the line. So what’s the problem here? I think the logic for connecting to the API can be separated from the Medium-specific work. There are four benefits to this:
- Once we start adding more GET and POST requests we’d inevitably start duplicating the cURL code. Duplication is evil.
- Without those great blocks of cURL code, our Medium logic will be much clearer and more focussed
- By creating a generic REST class we can make it available for other projects, saving yet more duplication
- Later on, we might want to support alternative network/REST tools. Separating out the cURL code is a step towards easily supporting that.
So, here’s the cURL class which I’ve named CurlService.
class CurlService
{
private string $baseUrl;
private array $headers = [];
public function __construct(string $baseUrl)
{
$this->baseUrl = $baseUrl;
$this->setHeader("Content-Type", "application/json");
}
public function setHeader($key, $header): void
{
$this->headers[$key] = $header;
}
public function getHeaders(): array
{
$ret = [];
foreach ($this->headers as $key => $header) {
$ret[] = "{$key}: $header";
}
return $ret;
}
public function get(string $endpoint, array $args = []): \stdClass
{
$url = $this->baseUrl . $endpoint;
if (!empty($args)) {
$url .= '?' . http_build_query($args);
}
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $this->getHeaders());
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
$info = curl_getinfo($ch);
if ($info['http_code'] != 200) {
throw new \Exception("GET error for: $url: $response");
}
curl_close($ch);
return json_decode($response);
}
public function post(string $endpoint, array $data): \stdClass
{
$data = json_encode($data);
return $this->doPost($endpoint, $data);
}
private function doPost(string $endpoint, array|string $data): ?\stdClass
{
$url = $this->baseUrl . $endpoint;
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_HTTPHEADER, $this->getHeaders());
curl_setopt($ch, CURLOPT_POST, true);
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
$response = curl_exec($ch);
$info = curl_getinfo($ch);
if ($info['http_code'] != 201) {
throw new \Exception("POST error for: $url: $response");
}
curl_close($ch);
return json_decode($response);
}
}
As is best practice when refactoring, I’ve changed no functionality here. I’m simply rearranging my code a little. One quirk you may have noticed is my odd separation of post() and doPost(). The post() method simply JSON encodes the payload before passing it along to doPost() which is responsible for making the connection. This is a little piece of foreshadowing. In the next section, I’ll add another method which calls doPost().
Here’s my amended Medium class, which I’m now going to name MediumPoster.
class MediumPoster
{
private CurlService $service;
private string $workingdir;
public function __construct($intToken, $workingdir = "")
{
$this->intToken = $intToken;
$this->workingdir = $workingdir;
$this->service = new CurlService('https://api.medium.com/v1');
$this->service->setHeader("Authorization", "Bearer {$intToken}");
}
public function getMe(): \stdClass
{
return $this->service->get("/me");
}
public function addArticle(string $title, string $content): \stdClass
{
$endpoint = '/users/' . $this->getMe()->data->id . '/posts';
$data = [
'title' => $title,
'contentFormat' => 'markdown',
'content' => $content,
'publishStatus' => 'draft'
];
return $this->service->post($endpoint, $data);
}
}
That hard-coded instantiation of CurlService in the constructor is a little whiffy (it is, in other words, a code smell). I will probably refactor further at some point and accept a Service instance as a constructor argument (thereby making the class amenable to dependency injection). For now, though, I’m happy enough with what I have. I’m ready to add some more functionality.
So, what’s missing? Oh yes. Support for images.
Uploading an image
The endpoint for image upload is POST /images. Unlike all other endpoints it expects its payload in multipart form-encoded data – the same format a browser uses to send form data to a server. Thanks to our refactor, the MediumPoster class won’t have to bother itself with the petty details of sending its data to the API.
// MediumPoster
public function uploadImage(string $imagePath): ?string
{
$endpoint = '/images';
$url = $this->service->postBin($endpoint, "image", $imagePath);
return $url->data->url ?? null;
}
Simple, right? Well, yes, but that’s partly because I’ve punted some small complexity off to CurlService. I call a method named postBin() that does not yet exist. Let’s get that done:
// CurlService
public function postBin(string $endpoint, string $fieldname, string $filepath): \stdClass
{
if (! file_exists($filepath)) {
throw new \Exception("no file at '{$filepath}'");
}
$cfile = new \CURLFile($filepath, mime_content_type($filepath), basename($filepath));
$data = [
$fieldname => $cfile
];
$this->setHeader("Content-Type", "multipart/form-data");
$ret = $this->doPost($endpoint, $data);
$this->setHeader("Content-Type", "application/json");
return $ret;
}
In fact, we’ve done most of the work for this functionality already in the doPost() method. We check that the provided $filepath is valid and configure a CurlFile object. The CurlFile constructor accepts a path to a binary, a MIME type, and a filename. Thanks to the provided $filepath and PHP’s mime_content_type() function we have all we need to comply. Once we have created this object, we need to construct a simple data structure organised just like an HTML form submission in name/value pairs. Our name here was required in the $fieldname argument. The Medium API /images endpoint requires ‘image’ as its sole field name. We provided that key in our call at MediumPoster::uploadImage(). Finally, we set the Content-Type header which describes the format we’ll be sending to the API and call doPost() to send our payload.
NOTE We should probably, at some point, create a Guzzle implementation of our
Serviceclass as a further refactor. That will be likely be more resilient than this quick cURL version.
Let’s put the method through its paces.
$img1 = realpath(__DIR__ . "/../res/medium1.png");
$poster = new MediumPoster($token);
$url = $poster->uploadImage($img1);
Now for a quick browser check.
Yes, that seems to have worked nicely. So are we done? Well not really. We do need to automate the image uploads and, since the locations of our images will be changing, we’ll also need to amend the Markdown content before we send it to the API. Time for regular expression fun.
Automating image uploads and altering image tags
OK, I admit it. Regular expressions are not always fun – at least not for me. But they are useful. Our final mission is to parse the content passed in to addArticle() for image tags. Where we find one that references a local file, we’ll need to call uploadImage() and alter the URL in the tag to reflect the new location.
After quite a lot of ‘fun’, here is my reqular expression for matching Markdown image tags:
$regexp = '!\[(.*?)\]\s*\((\S+)(?:\s+([\'"])(.*?)\3)?\s*\)';
This is designed to handle the following formats:



Let’s break the regular expression down (feel free to ignore this if your heart is sinking – just use it, or find a better one. There’s a nice alternative example at Stack Overflow).
| Description | Regex | Explanation |
|---|---|---|
| Start and alt block | !\[(.*?)\] |
![ followed by any characters (as few as possible) followed by ]. The brackets around .* record the first backreference (which means we’ll be able to pull the matched content out of a $matches array). |
| Forgive a little space | \s* |
zero or more spaces |
| Open the URL section and grab the URL | \((\S+) |
The open brackets character( (the backslash means we treat the character as a literal). Then, bracketed for a second backreference, one or more non-space characters. |
| The title (if any) | (?:\s+([\'"])(.*?)\3)? |
(?:, and the corresponding ) at the end, group this sub-expression without making it available as a backreference. The sub-expression itself matches \s+ – one or more space characters. Then ([\'"]) – captured for backreference number three, a quote character. Then (.*?)\3 – any number of characters, as few as possible (captured for backreference four) followed by that third backreference. This last is a neat trick – it means that if the matched string started the title string off with a single character, that’s the character we will use to match the end. The final ? denotes zero or one. In other words, we’ll accept a title or no title at all |
| More space forgiveness and close the URL section | \s*\) |
Zero or more spaces followed by the close brackets literal |
Whew. I bet you didn’t bother to read the contents of that table. Anyway, I now have a half-decent regular expression. Here’s how I use it:
public function parseArticle($content): string
{
$regexp = '!\[(.*?)\]\s*\((\S+)(?:\s+([\'"])(.*?)\3)?\s*\)';
// this callback will invoke an upload for local files
// and replace the local path with the uploaded URL
$func = function ($a) {
$alt = $a[1];
$url = $a[2];
if (preg_match("/^http[s]{0,1}:/i", $url)) {
// ignore non-local URLs
return $a[0];
}
$path = $this->workingdir . $url;
if (! file_exists($path)) {
error_log("unable to locate local file '$path'");
return $a[0];
}
$title = "";
if (! empty($a[3]) && ! empty($a[4])) {
// rebuild title
$title = " {$a[3]}{$a[4]}{$a[3]}";
}
$url = $this->uploadImage($path);
if (is_null($url)) {
return $a[0];
}
return "";
};
return preg_replace_callback("/{$regexp}/", $func, $content);
}
So most of this method is actually a callback (stored in the variable $func) designed to be plugged in to the preg_replace_callback() function. preg_replace_callback() invokes the callback for every match it finds, passing it an array of matches. That’s where the backreferences I emboldened in the table above will come into their own. The array provided to the callback will always contain the entire match in its first element. Each subsequent element will contain a corresponding backreference. The callback should return a string value, which the preg_replace_callback() function uses to replace the current match.
The $func callback, then, should have all it needs to upload an image and to reconstruct the image tag. The construction of the regular expression guarantees at least two backreferences, giving us the alt value and the URL. We test the url for a leading ‘http’ or ‘https’. If these match, then we don’t get involved – it’s a non-local image. Otherwise we check that the path points to a an existing file (using a leading path if provided). If things look sane, we can finally call uploadImage(). Then, we reconstruct the image tag (including the title part, if matched) using the upload URL.
All we need to do now is make sure that parseArticle() is called at the right time. That requires a simple amend to addArticle():
public function addArticle(string $title, string $content): \stdClass
{
$content = $this->parseArticle($content);
$endpoint = '/users/' . $this->getMe()->data->id . '/posts';
$data = [
'title' => $title,
'contentFormat' => 'markdown',
'content' => $content,
'publishStatus' => 'draft'
];
return $this->service->post($endpoint, $data);
}
Bringing it together
Despite the level of detail here, these two classes weigh in at under 200 lines of code. My example source is full of the comments I use to extract listings (that might be a topic for a future article) so I’ve created a couple of GitHub gists. Here is a clean version of the CurlService class. This is MediumPoster.
Let’s test them. I’m going to run the code against a previous article about the Unsplash API.
$token = getToken();
$poster = new MediumPoster($token, $basedir);
$contents = file_get_contents($basedir . "/_posts/2023-02-03-automate-unsplash-with-php-and-api.md");
$poster->addArticle("Automating Unsplash for attribution", $contents);
I run the code, and here is the draft, sitting in Medium, awaiting final checks and tweaks!
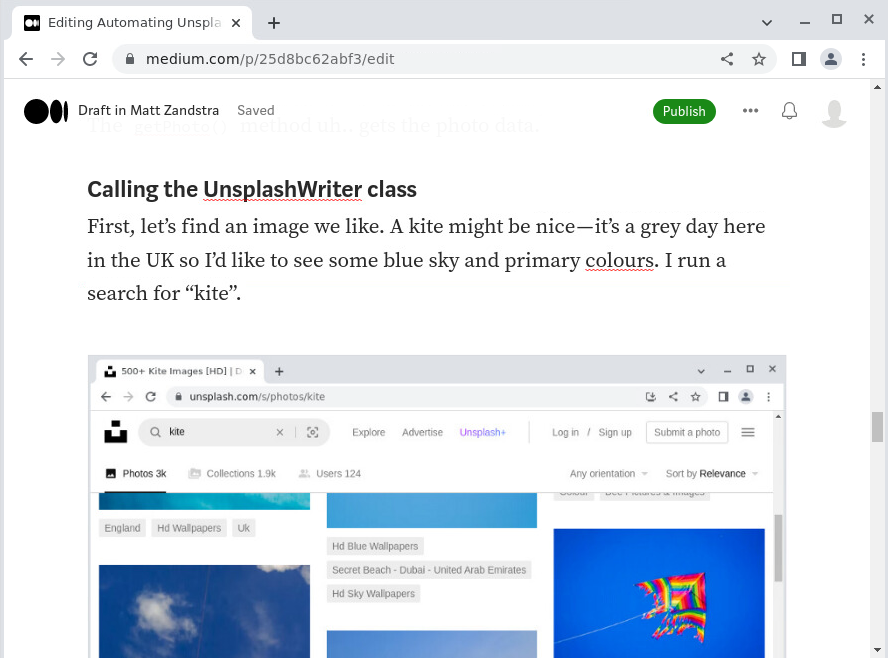
What next?
You’ll likely want to create a neat CLI or Web tool to use your (no doubt much cooler and better-featured) version of the MediumPoster class. Other enhancements might include fixing up local links so that they point to a production version of your article, detecting code blocks so that you don’t translate image tags that are part of code examples, and maybe switching out the cURL service class for a Guzzle equivalent. Although the regular expression presented here is fine for a quick working example, if I needed something robust I would likely source a Markdown library from Packagist and use that instead for my matching and substitution.
Conclusion
Don’t forget to check out the Medium API documentation and blog for more on automating the platform and developing Medium itself.
The story (local link) I sent to Medium is now live there.
You can find source code for all my recent articles on GitHub. The code for this article is in the 011-medium directory. There are also clean gists for CurlService and MediumPoster.
Photo by Dawid Zawiła on Unsplash

